SlimInfer paper is accepted by AAAI 2026!
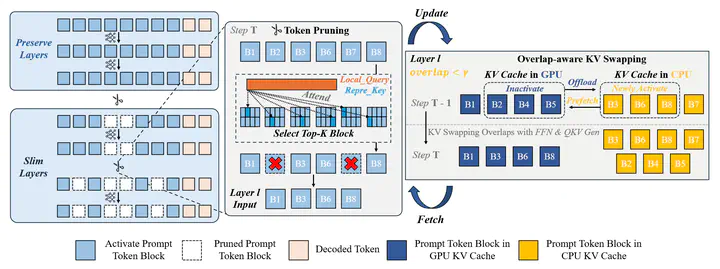
👏 Paper title: SlimInfer: Accelerating Long-Context LLM Inference via Dynamic Token Pruning. In this paper, we identify an information diffusion phenomenon in LLMs, where information from critical tokens spreads across the sequence, allowing aggressive pruning in later layers. Based on this insight, we propose SlimInfer, an inference framework that performs dynamic block-wise pruning on hidden states and introduces a predictor-free, asynchronous KV cache manager. This approach efficiently overlaps I/O with computation, achieving up to 2.53× TTFT speedup and 1.88× end-to-end latency reduction on LLaMA-3.1-8B-Instruct without sacrificing accuracy on long-context benchmarks. [related project]