Computational Intelligence Laboratory @ Beihang University
CI-Lab is a Research Group affiliated with the Institute of Advanced Computing Technology (ACT), School of Computer Science and Engineering (SCSE), Beihang University (BUAA).

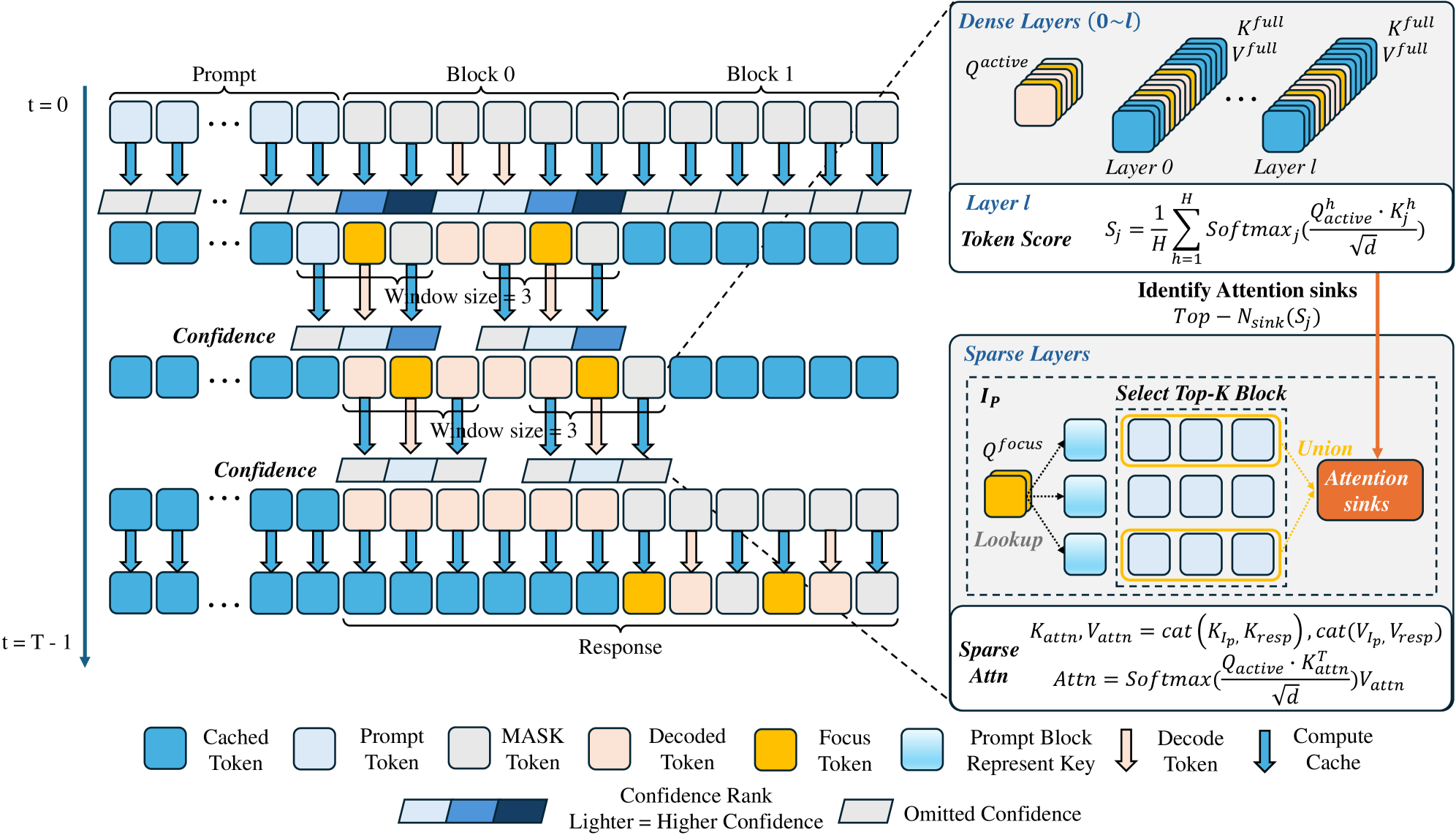
Paper title: Focus-dLLM: Accelerating Long-Context Diffusion LLM Inference via Confidence-Guided Context Focusing. We propose Focus-dLLM for long-context diffusion LLM inference. It uses confidence-guided context focusing and sink-aware pruning to reduce redundant bidirectional attention without retraining.
GitHub: Longxmas/Focus-dLLM
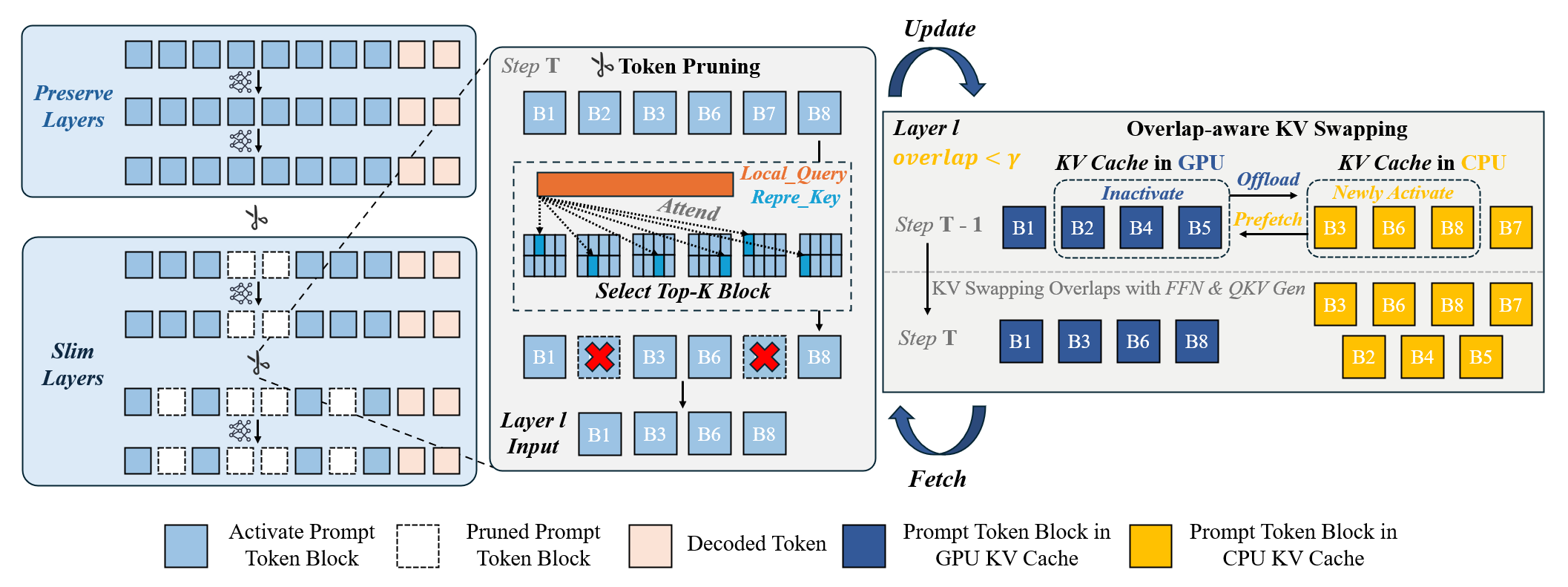
Paper title: SlimInfer: Accelerating Long-Context LLM Inference via Dynamic Token Pruning. We propose SlimInfer for long-context LLM inference. It uses dynamic block-wise token pruning and a predictor-free asynchronous KV cache manager to reduce prefill latency, memory pressure, and I/O overhead.
GitHub: Longxmas/SlimInfer
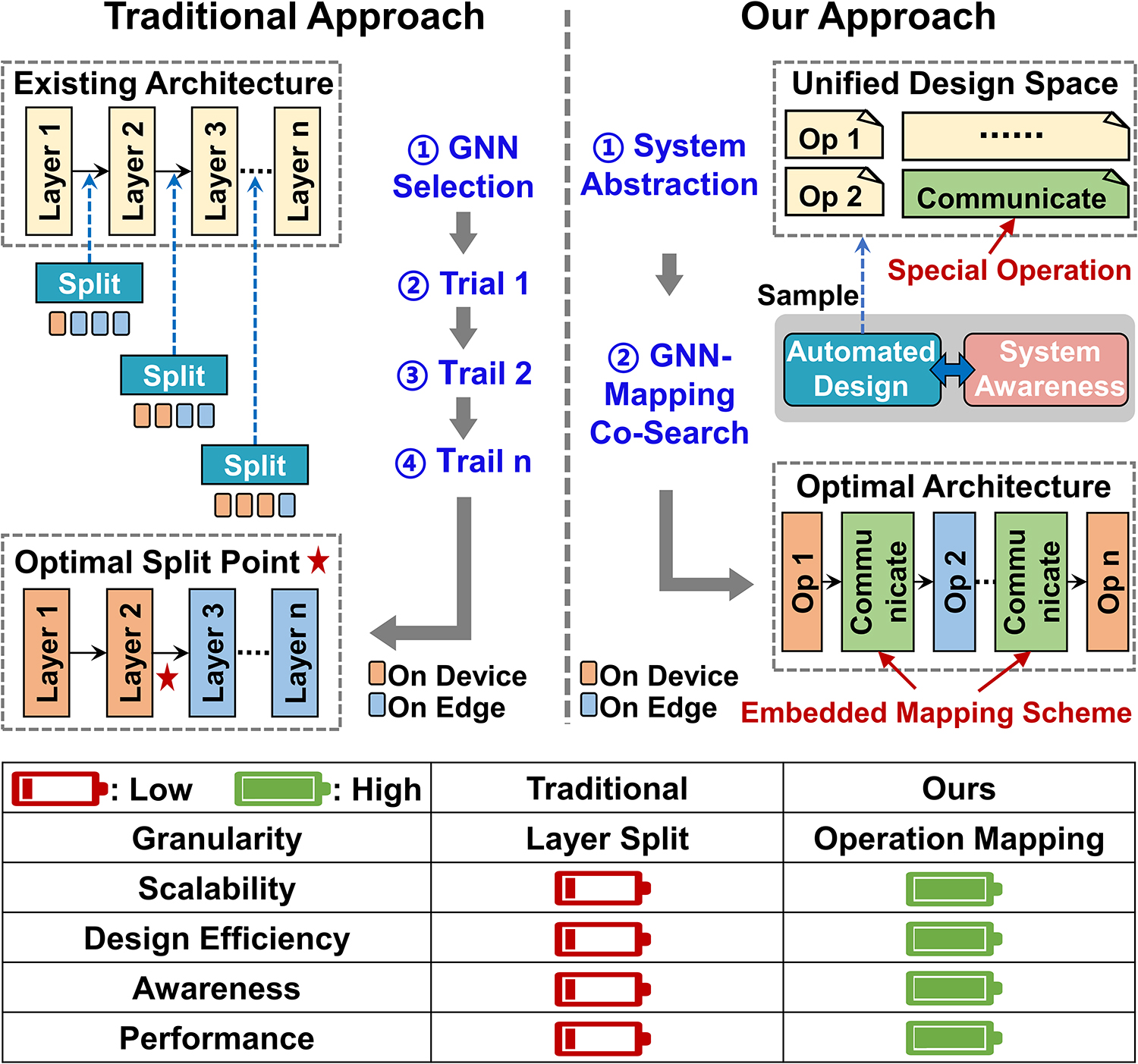
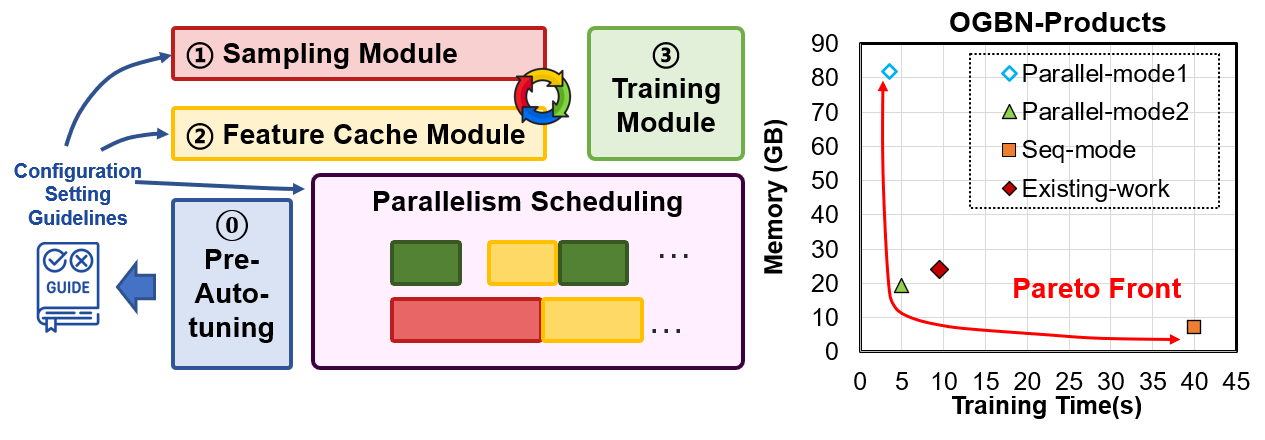
Paper title: Towards Affordable, Adaptive and Automatic GNN Training on CPU-GPU Heterogeneous Platforms. We introduce A3GNN for adaptive GNN training on CPU-GPU platforms. It combines locality-aware sampling and fine-grained scheduling to balance throughput, memory footprint, and training quality on heterogeneous systems.
GitHub: BUAA-CI-LAB/A3GNN
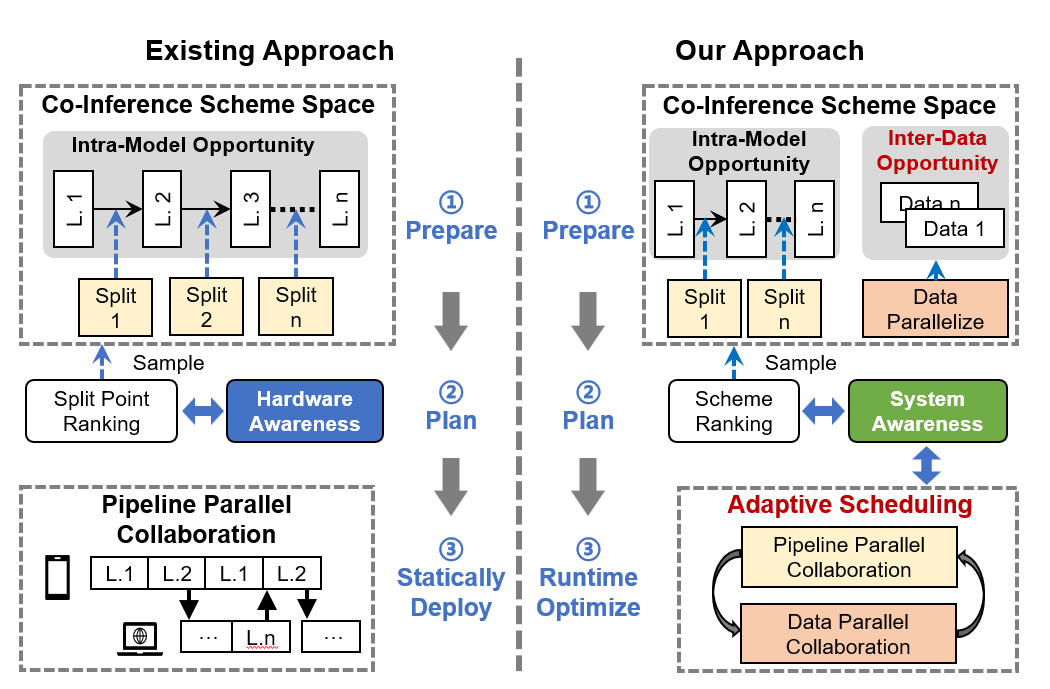
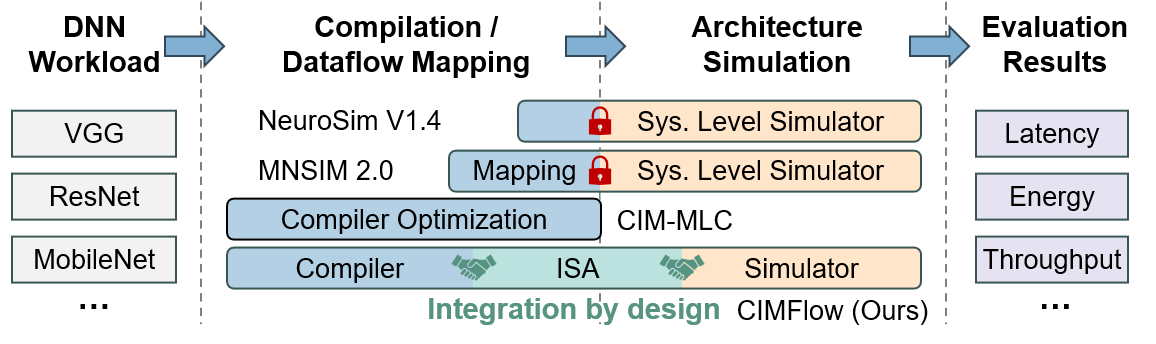
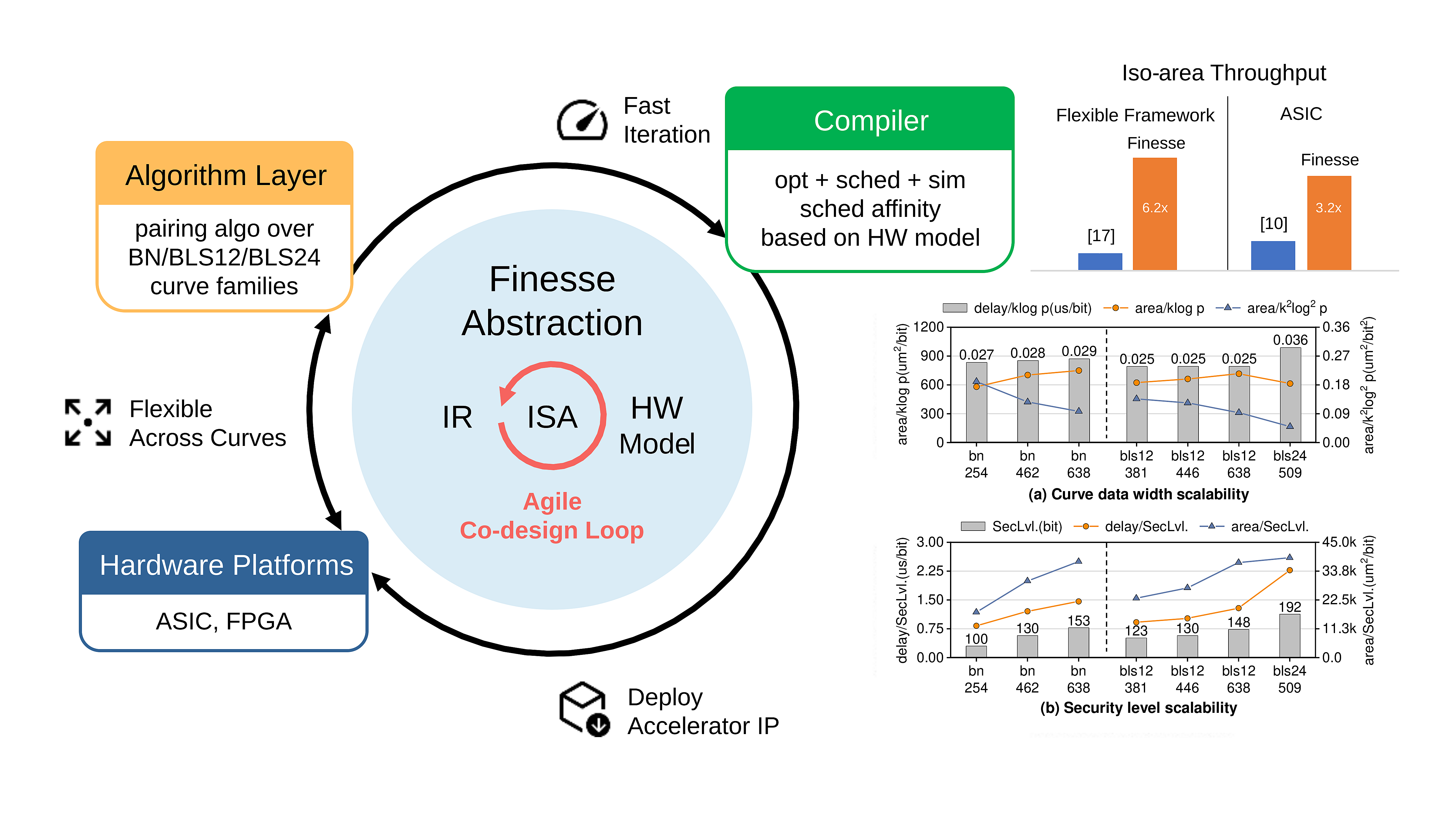
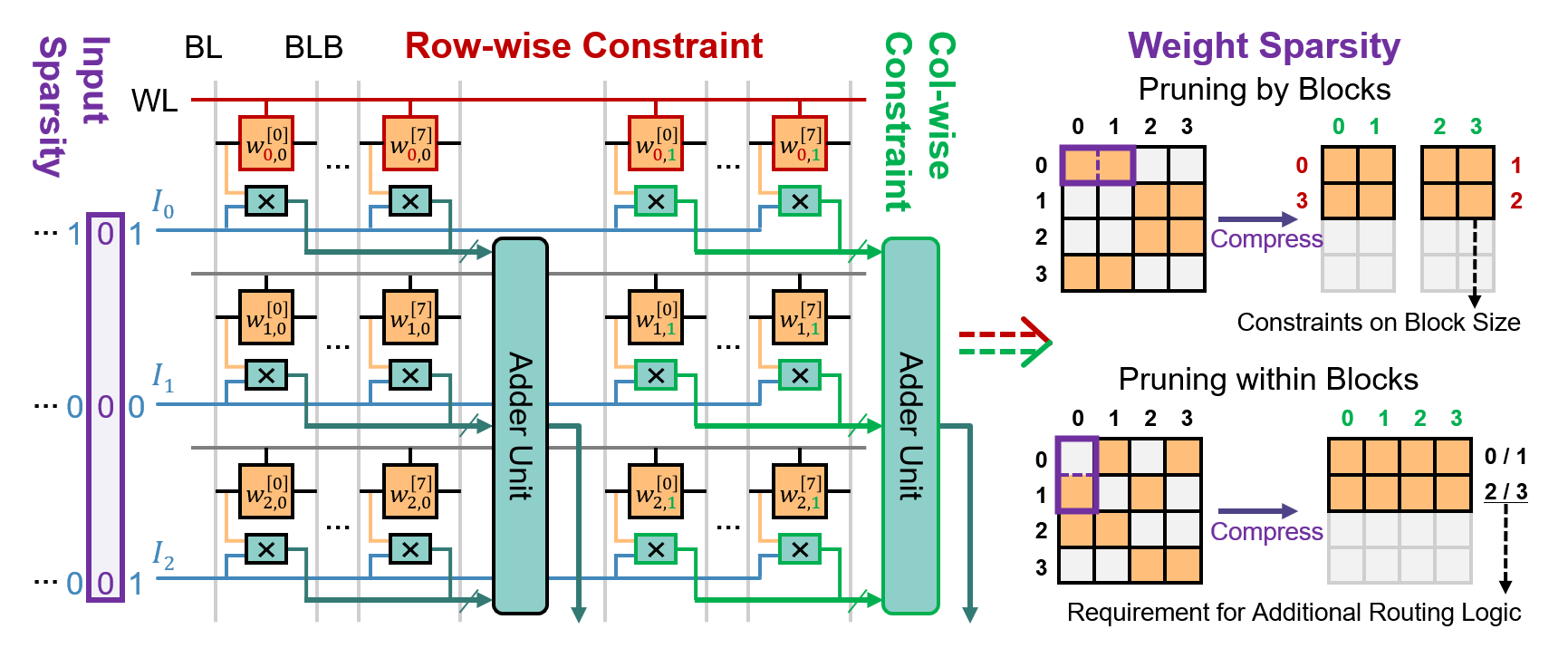
Paper title: Finesse: An Agile Design Framework for Pairing-based Cryptography via Software/Hardware Co-Design. We introduce Finesse, a software-hardware co-design framework for pairing-based cryptography. It integrates compiler support, simulation, and parameterized pipelined hardware to speed up accelerator design and execution.
GitHub: BUAA-CI-LAB/Finesse