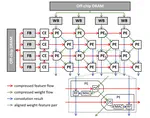
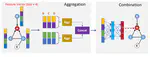
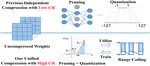
👏 Paper title: Lossy and Lossless (L2) Post-training Model Size Compression. We propose a unified post-training model size compression method that combines lossy and lossless compression techniques, with a parametric weight transformation and a differentiable counter to guide optimization. Our method achieves a stable 10× compression ratio without accuracy loss and a 20× ratio with minimal accuracy degradation, all while easily controlling the global compression ratio and adapting it for different layers. [related project]
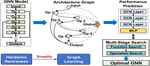
👏 Paper title: Hardware-Aware Graph Neural Network Automated Design for Edge Computing Platforms. We explore a hardware-aware GNN architecture design for edge devices, leveraging the novel idea of “predicting GNNs with GNNs” to efficiently estimate the performance of candidate architectures during the NAS process. By thoroughly analyzing the impact of device heterogeneity on GNN performance and integrating hardware awareness into the exploration, our method achieves significant improvements in both accuracy and efficiency. [related project]
👏 Paper title: NAND-SPIN-Based Processing-in-MRAM Architecture for Convolutional Neural Network Acceleration. In this work, we propose a NAND-SPIN-based PIM architecture for efficient convolutional neural network (CNN) acceleration. [related project]

👏 Paper title: Reconfigurable and Dynamically Transformable In-Cache-MPUF System With True Randomness Based on the SOT-MRAM. In this paper, we present a reconfigurable Physically Unclonable Functions (PUF) based on the Spin-Orbit-Torque Magnetic Random-Access Memory (SOT-MRAM), which exploits thermal noise as the true dynamic entropy source. [related project]
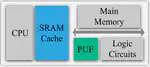
👏 Paper title:Accelerating Graph Connected Component Computation with Emerging Processing-In-Memory Architecture. In this article, we propose to accelerate CC computation with the emerging processing-in-memory (PIM) architecture through an algorithm–architecture co-design manner. [related project]
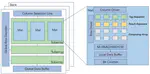
👏 Paper title: Eventor: An Efficient Event-Based Monocular Multi-View Stereo Accelerator on FPGA Platform. In this paper, Eventor is proposed as a fast and efficient EMVS accelerator by realizing the most critical and time-consuming stages including event back-projection and volumetric ray-counting on FPGA. [related project]
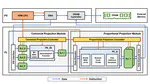
👏 Paper title: Triangle Counting Accelerations: From Algorithm to In-Memory Computing Architecture. In this paper, we propose to accelerate TC with the emerging processing-in-memory (PIM) architecture through an algorithm-architecture co-optimization manner. [related project]
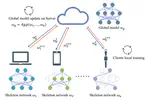
👏 Paper title: FedSkel: Efficient Federated Learning on Heterogeneous Systems with Skeleton Gradients Update. In this work, we propose FedSkel to enable computation-efficient and communication-efficient federated learning on edge devices by only updating the model’s essential parts, named skeleton networks. [related project]
👏 Paper title: S2Engine: A Novel Systolic Architecture for Sparse Convolutional Neural Networks. In this work, we propose S2Engine – a novel systolic architecture that can fully exploit the sparsity in CNNs with maximized data reuse. [related project]