👏 Paper title: Towards Affordable, Adaptive and Automatic GNN Training on CPU-GPU Heterogeneous Platforms. In this paper, we introduces A3GNN, a framework for Affordable, Adaptive, and Automatic GNN training on heterogeneous CPU-GPU platforms. It improves resource usage through locality-aware sampling and fine-grained parallelism scheduling. Moreover, it leverages reinforcement learning to explore the design space and achieve pareto-optimal trade-offs among throughput, memory footprint, and accuracy. [related project]
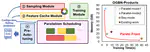
👏 Paper title: ACE-GNN: Adaptive GNN Co-Inference with System-Aware Scheduling in Dynamic Edge Environments. In this work, we present ACE-GNN, the first adaptive GNN co-inference framework for dynamic edge environments. By integrating system-level abstraction with novel prediction methods, ACE-GNN enables rapid runtime scheme optimization and adaptive scheduling between pipeline and data parallelism. Coupled with efficient batching and specialized communication middleware, ACE-GNN achieves up to 12.7× speedup and 82.3% energy savings, significantly outperforming existing co-inference solutions. [related project]
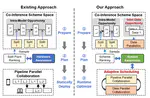
👏Paper title: CIMFlow: An Integrated Framework for Systematic Design and Evaluation of Digital CIM Architectures
In this paper, we introduce CIMFlow, an integrated framework that systematically bridges compilation and simulation with a flexible ISA tailored for digital Compute-in-Memory (CIM) architectures. CIMFlow addresses critical design challenges such as limited SRAM capacity through advanced partitioning and parallelism strategies, providing comprehensive and flexible exploration capabilities for digital CIM architecture design. Compared to existing tools, CIMFlow significantly improves exploration flexibility and performance, achieving up to 2.8× speedup and 61.7% energy reduction across various deep learning workloads.
[related project]
👏Paper title: Finesse: An Agile Design Framework for Pairing-based Cryptography via Software/Hardware Co-Design. This work tackles the challenges of lengthy design cycles and high re-engineering costs in PBC accelerators, which hinder adaptation to evolving cryptographic demands. Finesse introduces a co-design framework featuring a unified IR/ISA/hardware abstraction, a parameterized pipelined architecture, and an optimizing compiler. This enables rapid iteration and efficient design space exploration. Finesse achieves up to 6.2x higher iso-area throughput than prior flexible designs, and outperforms specialized ASICs by up to 3.2×. [Related Project]

👏 Paper title: Efficient SRAM-PIM Co-Design by Joint Exploration of Value-Level and Bit-Level Sparsity. We propose Dyadic Block PIM (DB-PIM), a groundbreaking algorithm-architecture co-design framework to harness both value-level and bit-level sparsity in digital SRAM-PIM. It circumvents structured zero values in weights and bypasses unstructured zero bits within nonzero weights and block-wise all-zero bit columns in input features. As a result, the DB- 21 PIM framework skips a majority of unnecessary computations, thereby driving significant gains in computational efficiency. [related project]

👏 Paper title: GNNavigator: Towards Adaptive Training of Graph Neural Networks via Automatic Guideline Exploration. This work addresses the challenge of balancing training runtime, memory consumption, and accuracy in Graph Neural Networks (GNNs), which have seen significant success in various applications. GNNavigator introduces an adaptive GNN training configuration optimization framework. By leveraging a unified software-hardware co-abstraction, a novel GNN training performance model, and an effective design space exploration strategy, GNNavigator meets the diverse requirements of GNN applications. [related project]

👏 Paper title: Graph Neural Networks Automated Design and Deployment on Device-Edge Co-Inference Systems. In this paper, we abstract the communication process in device-edge co-inference into a specific operation, creating a unified design space for GNN architecture and co-inference schemes. Using random search, we achieve joint optimization, leading to a GNN architecture that integrates partitioning schemes, enabling a trade-off between communication and computation, and outperforming SOTA methods. [related project]

👏 Paper title: Towards Efficient SRAM-PIM Architecture Design by Exploiting Unstructured Bit-Level Sparsity. In this paper, we propose Dyadic Block PIM (DB-PIM), a groundbreaking algorithm-architecture co-design framework to exploit the unstructured bit-level sparsity effectively. First, we propose an algorithm coupled with a distinctive sparsity pattern to preserve the random distribution of non-zero bits while improving regularity. Then, we develop a custom PIM macro that includes dyadic block multiplication units (DBMUs) and Canonical Signed Digit (CSD)-based adder trees to achieve unstructured bit-level sparsity. Results show that our proposed co-design framework achieves a remarkable speedup of up to 6.53x and energy savings of 77.50%. [related project]
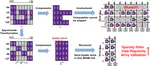
👏 Paper title: DDC-PIM: Efficient Algorithm/Architecture Co-Design for Doubling Data Capacity of SRAM-Based Processing-in-Memory. We propose DDC-PIM, an efficient algorithm/architecture co-design methodology that effectively doubles the equivalent data capacity of SRAM. By combining qvfilter-wise complementary correlation algorithm with a customized architecture, we can exploit the intrinsic cross-coupled structure of 6T SRAM to store the bitwise complementary pair in their complementary states (Q/QB), thereby maximizing the data capacity and integration density of each SRAM cell. [related project]

👏 Paper title: Architectural Implications of GNN Aggregation Programming Abstractions. This paper evaluates the architectural implications of programming abstractions for Graph Neural Network (GNN) aggregation. It introduces a taxonomy based on data organization and propagation methods and performs a comprehensive performance characterization across platforms and graph properties. Key findings include insights into abstraction selection, hardware adaptability, and the structural impact of graphs, providing valuable guidance for GNN acceleration research. [related project]
