Focus-dLLM accepted by ACL 2026: confidence-guided sparse attention for long-context diffusion LLM inference
👏 Paper title: Focus-dLLM: Accelerating Long-Context Diffusion LLM Inference via Confidence-Guided Context Focusing.
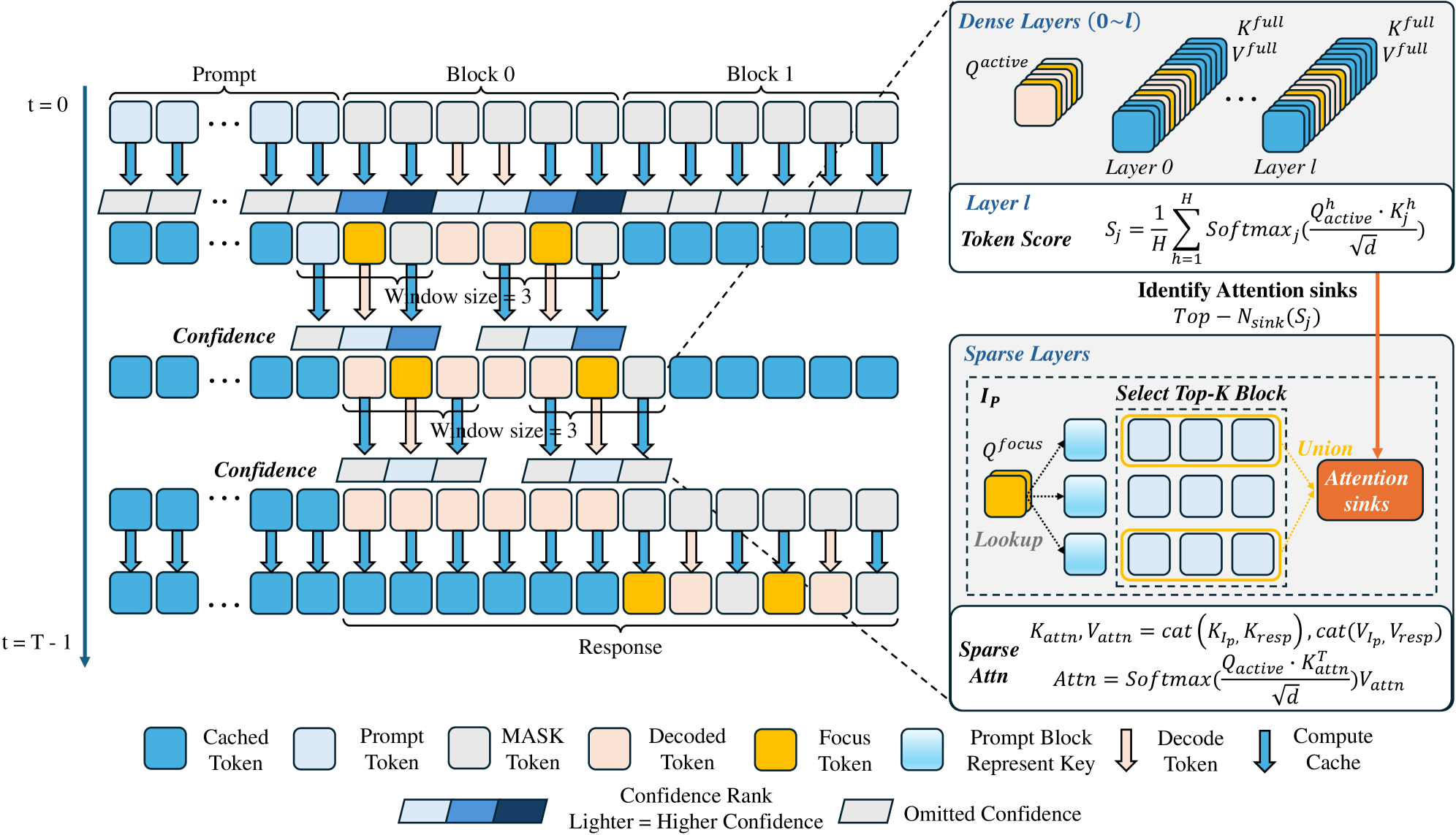
Focus-dLLM accelerates long-context diffusion large language model inference by reducing redundant bidirectional attention computation. Diffusion LLMs can process long contexts in a non-autoregressive decoding paradigm, but full attention over long sequences creates a major computational bottleneck.
The framework is training-free and uses past token confidence to predict the regions that should remain in focus during diffusion decoding. It then applies sink-aware pruning to remove redundant attention computation while preserving influential attention sinks. This design improves long-context dLLM efficiency without requiring model retraining or architectural changes.
Focus-dLLM is motivated by the observation that not every token contributes equally during every diffusion decoding step. As generation progresses, confidence signals can help identify which context regions are more important for subsequent denoising and which attention interactions are likely redundant.
By using these signals at inference time, the method provides a lightweight acceleration path for long-context dLLMs. It is particularly attractive because it preserves the original model parameters and can be applied without collecting new training data or modifying the model architecture.
GitHub: Longxmas/Focus-dLLM