SlimInfer accepted by AAAI 2026: dynamic token pruning for faster long-context LLM inference
👏 Paper title: SlimInfer: Accelerating Long-Context LLM Inference via Dynamic Token Pruning.
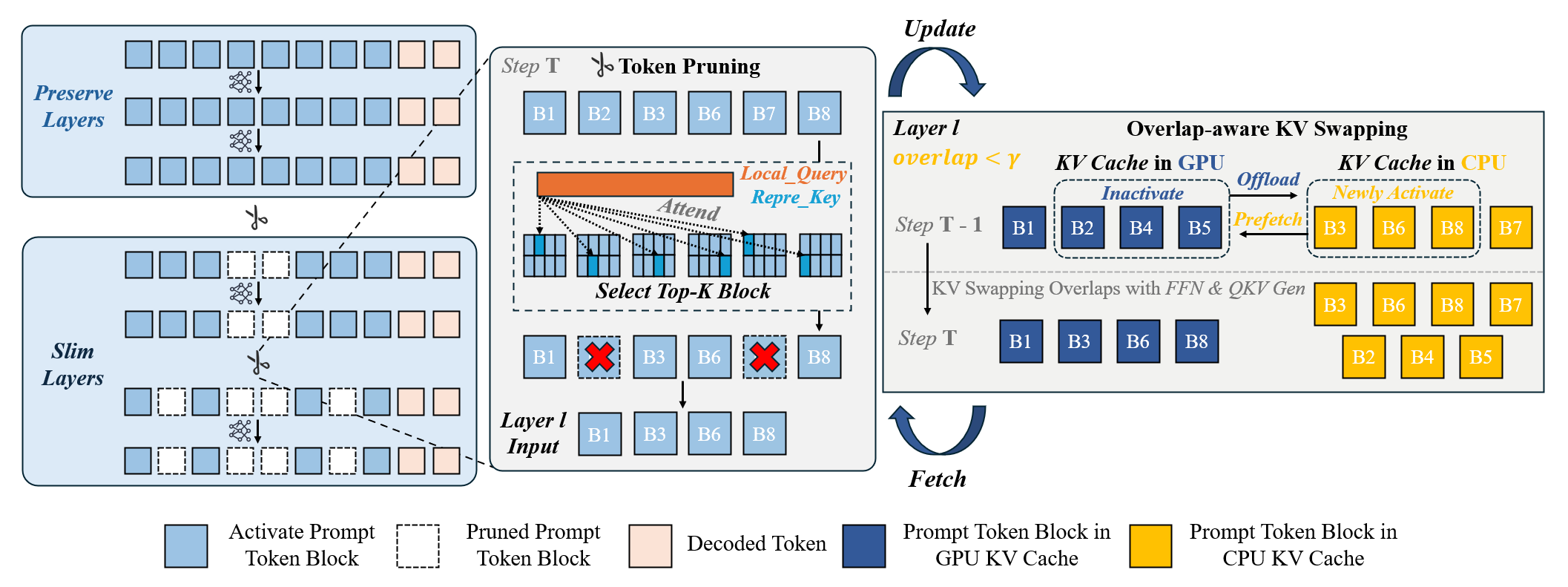
SlimInfer accelerates long-context LLM inference by pruning less critical prompt tokens during the forward pass. Long-context serving is often limited by prefill computation, hidden-state processing, and KV cache memory pressure, so reducing only attention cost is not enough for full-system acceleration.
The framework uses a layer-wise, block-wise pruning strategy motivated by the information diffusion phenomenon: as important context information propagates through the network, later layers can preserve semantic behavior with fewer active hidden states. SlimInfer pairs this pruning mechanism with a predictor-free asynchronous KV cache manager, reducing computation, memory use, and I/O overhead while maintaining long-context task quality.
SlimInfer is designed to improve the full inference pipeline rather than a single isolated kernel. By pruning hidden states during prefill and coordinating KV cache updates asynchronously, it targets both computation and system-level memory movement.
This makes the framework valuable for serving long-context applications, where latency and memory footprint grow quickly with sequence length. It offers a practical acceleration strategy that does not require retraining the LLM or adding a separate prediction model.
GitHub: Longxmas/SlimInfer