A3GNN accepted by ICCD 2025: affordable, adaptive, and automatic GNN training on CPU-GPU platforms
👏 Paper title: Towards Affordable, Adaptive and Automatic GNN Training on CPU-GPU Heterogeneous Platforms.
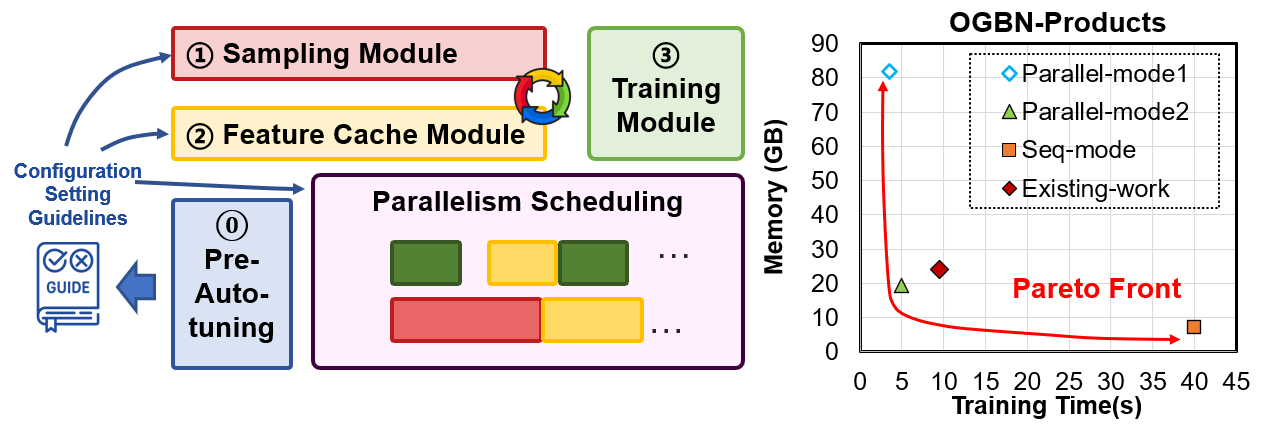
A3GNN targets practical GNN training on CPU-GPU heterogeneous platforms, where performance depends on how graph sampling, feature access, and computation are divided across devices. Static training recipes can underuse available hardware or exceed memory limits as graph and model characteristics change.
The work introduces an adaptive training flow that coordinates locality-aware sampling with fine-grained scheduling. By balancing throughput, memory footprint, and accuracy, A3GNN aims to make high-performance GNN training more affordable and automatic on commodity heterogeneous platforms.
A3GNN is designed for the reality that many labs and deployment environments rely on mixed CPU-GPU resources rather than large specialized clusters. The framework adapts training decisions to the platform so that available compute and memory can be used more effectively.
The contribution is not only faster execution but also a more automatic training workflow. By reducing manual tuning pressure, A3GNN helps make GNN training more accessible on practical heterogeneous hardware setups.
GitHub: BUAA-CI-LAB/A3GNN