L2 compression accepted by ICCV 2023: unified lossy and lossless post-training model size compression
👏 Paper title: Lossy and Lossless (L2) Post-training Model Size Compression.
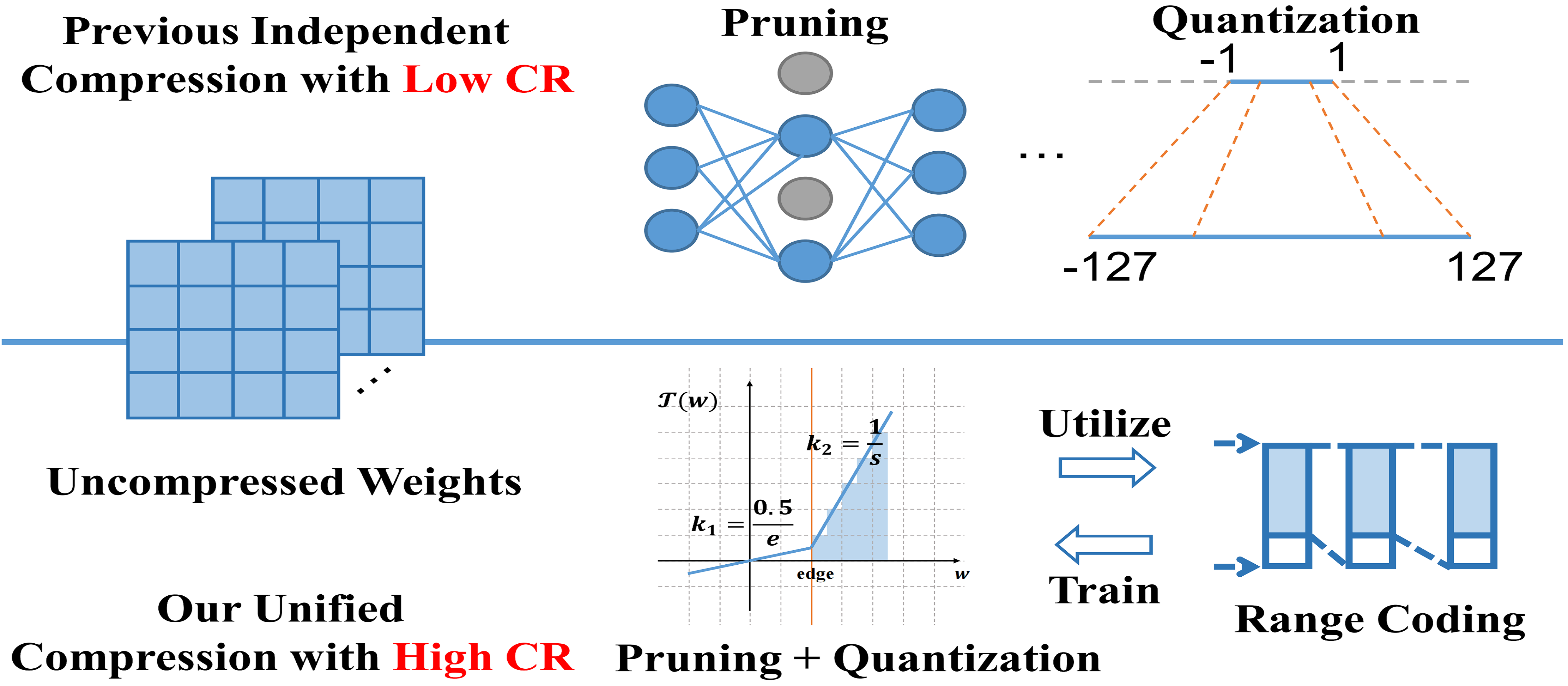
The L2 compression framework addresses the storage and transmission cost of deep neural networks after training. Instead of treating lossy and lossless compression as separate steps, the paper combines them into a unified post-training workflow.
The method introduces a parametric weight transformation to coordinate different lossy compression choices and a differentiable counter to guide optimization toward a compression-friendly representation. It can target a desired global compression ratio, allocate adaptive compression across layers, and preserve model accuracy while substantially reducing model size.
Unlike approaches that rely only on quantization, pruning, or generic entropy coding, L2 treats the compression pipeline as a coupled optimization problem. This lets the framework reason about how weight transformation affects downstream lossless encoding.
The result is useful for model deployment scenarios where storage, transmission, or on-device memory is constrained. By operating after training, L2 also provides a practical compression option for existing models without requiring a full retraining pipeline.