FedSkel accepted by CIKM 2021: efficient federated learning with skeleton gradient updates
👏 Paper title: FedSkel: Efficient Federated Learning on Heterogeneous Systems with Skeleton Gradients Update.
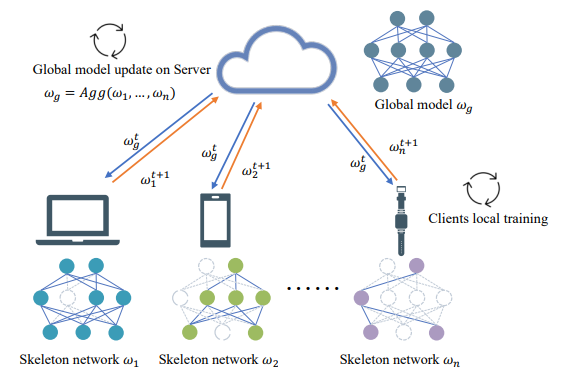
FedSkel addresses the efficiency bottleneck of federated learning on heterogeneous edge devices, where clients often have very different compute capability, network bandwidth, and data distributions. Instead of updating the full model on every device and transmitting all gradients, FedSkel identifies compact skeleton networks that preserve the most essential model updates.
The framework updates only these skeleton gradients, reducing local back-propagation cost and communication traffic while keeping the learning process effective. This makes federated learning more practical for resource-constrained and imbalanced edge environments, where privacy-preserving training must also respect device-level limitations.
From a system perspective, FedSkel is useful because it attacks both major costs in federated learning: the amount of local work performed by each client and the volume of updates exchanged with the server. This is especially important when edge clients differ widely in hardware capability or network quality, since the slowest or weakest devices can otherwise limit the overall training process.
The result is a more deployment-oriented federated learning strategy. Rather than assuming all clients can afford full-gradient training, FedSkel adapts the update workload to the essential structure of the model, helping heterogeneous clients participate more efficiently without abandoning collaborative learning.